MonitoringSucks and we didn't fix it.
Earlier this week Inuits hosted a 2 day hackfest titled #MonitoringSucks. A good number of people with a variety of backgrounds showed up on monday morning. I don't know why but people had high expectations for this event , did they really expect us to fix the #monitoringsucks problem in a mere 2 days ?
Next to myselve we had Patrick Debois , Grégory Karékinian, Stefan Jourdan, Colin Humphreys, Andrew Crump, Ohad Levy , Frank Marien, Toshaan Bharvani, Devdas Bhagat, Maciej Pasternacki Axel Beckert Jelle Smet, Noa Resare @blippie , John John Tedro @udoprog, Christian Trabold @ctrabold and obviously some people I missed
A good mixture of Fosdem visitors that stayed a litte longer in our cold country and locals with ideas. We had people from TomTom, RedHat , Spotify, Booking.com, Inuits, Atlassian, coming from Belgium, The Netherlands France, Israel, the UK, Sweden, Germany, Poland and Switzerland if I`m not mistaken.
The format was pretty open, much of the first day was spend around the drawingboard.

(Ohad Levy, Jelle Smet, PatrickDebois and Frank Marien) discussing a variety of topics
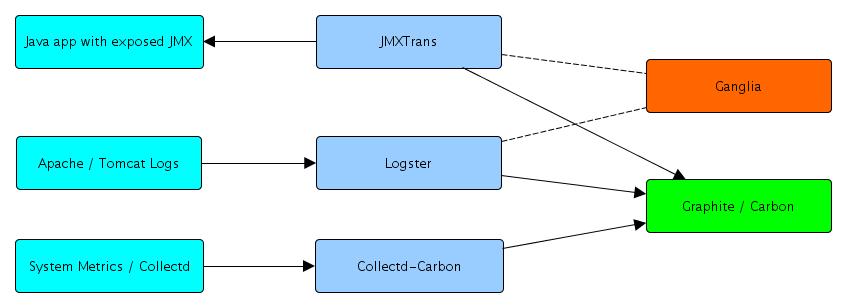
This monitoring topic is complex, there are different areas that need to be covered. The drawing below documents how we splitted the problem into different areas , and listed the different tools people use for these areas.
- Collection: Collectd, Nagios, Ganglia
- Transport: XMPP, Smiple, Smtp, 0mq , APMQ, rsyslog, irc, stomp
- Storage : rrd, graphite, opentsdb, hbase,
- Filtering: logstash, esper,
- Visualisation : Graphite,
- Notifcation: PagerDuty
- Reporting: Jasper
Obviously above list is far from complete.

The afternoon discussion continued where we left of before lunch, just after the powercut. Only now we started refocussing on filtering and aggregating values using Logstash
@patrickdebois had been talking about the idea to use Logstash as a way to collect data , transform it and throw it either to another tool, or onto a Queue before.
Looking at Logstash it makes kind of sense. Logstash already has a zillion of input types, filters and outputs. Including popular queues such as amqp and zeromq. Yes, the default behaviour for a lot of people is to get data from different inputs, filter it and then send it to ElasticSearch, but much more is possible with the available outputs.

It was only on tuesday that people really started writing code
So what did really come out of the #monitoringsucks hackfest. ?
A couple of people were working on packaging existing tools for their favourite distro. Others were working on integrating a number of other already existing tools (e.g Patrick working on more inputs for Logstash., me working on replacing logster with Logstash, setting up Kibana etc. New tools were learned, items were added to todolists (Kibana, (doesn't work on older Firefox instances) Tattle, statsd) and items were scratched from todolists (Graylog2 (Kibana replaces that as a good Frontend for Logstash) )
A lot of experiences with different tools were exchanged
Frank Marien showed us a demo of his freshly release ExtremeMon framework. A really promising project.
The sad part about a workshop like this one is that you enter with a bunch of ideas , and leave with even more ideas, hence more work. We haven't solved the problem yet, but a lot of more people are now thiking about the problem and how to solve it a more modulare (unix style) approach. With different litte tools, all being good at something and all being interconnectable.