This is a repost of an article I wrote for the Acquia Blog some time ago.
As mentioned before, devops can be summarized by talking about culture, automation, monitoring metrics and sharing. Although devops is not about tooling, there are a number of open source tools out there that will be able to help you achieve your goals. Some of those tools will also enable better communication between your development and operations teams.
When we talk about Continuous Integration and Continuous Deployment we need a number of tools to help us there. We need to be able to build reproducible artifacts which we can test. And we need a reproducible infrastructure which we can manage in a fast and sane way. To do that we need a Continuous Integration framework like Jenkins.
Formerly known as Hudson, Jenkins has been around for a while. The open source project was initially very popular in the Java community but has now gained popularity in different environments. Jenkins allows you to create reproducible Build and Test scenarios and perform reporting on those. It will provide you with a uniform and managed way to , Build, Test, Release and Trigger the deployment of new Artifacts, both traditional software and infrastructure as code-based projects. Jenkins has a vibrant community that builds new plugins for the tool in different kinds of languages. People use it to build their deployment pipelines, automatically check out new versions of the source code, syntax test it and style test it. If needed, users can compile the software, triggering unit tests, uploading a tested artifact into a repository so it is ready to be deployed on a new platform level.
Jenkins then can trigger an automated way to deploy the tested software on its new target platform. Whether that be development, testing, user acceptance or production is just a parameter. Deployment should not be something we try first in production, it should be done the same on all platforms. The deltas between these platforms should be managed using a configuration management tool such as Puppet, Chef or friends.
In a way this means that Infrastructure as code is a testing dependency, as you also want to be able to deploy a platform to exactly the same state as it was before you ran your tests, so that you can compare the test results of your test runs and make sure they are correct. This means you need to be able to control the starting point of your test and tools like Puppet and Chef can help you here. Which tool you use is the least important part of the discussion, as the important part is that you adopt one of the tools and start treating your infrastructure the same way as you treat your code base: as a tested, stable, reproducible piece of software that you can deploy over and over in a predictable fashion.
Configuration management tools such as Puppet, Chef, CFengine are just a part of the ecosystem and integration with Orchestration and monitoring tools is needed as you want feedback on how your platform is behaving after the changes have been introduced. Lots of people measure the impact of a new deploy, and then we obviously move to the M part of CAMS.
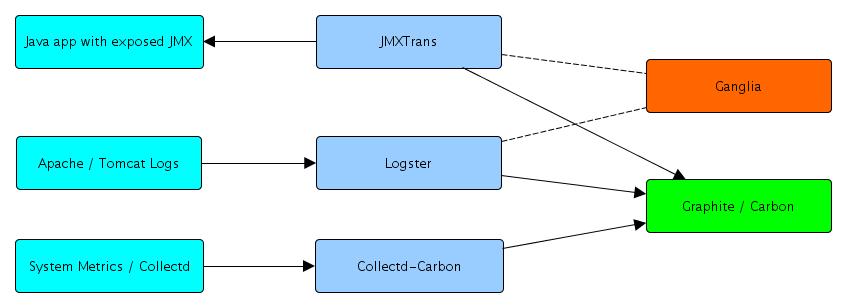
There, Graphite is one of the most popular tools to store metrics. Plenty of other tools in the same area tried to go where Graphite is going , but both on flexibility, scalability and ease of use, not many tools allow developers and operations people to build dashboards for any metric they can think of in a matter of seconds.
Just sending a keyword, a timestamp and a value to the Graphite platform provides you with a large choice of actions that can be done with that metric. You can graph it, transform it, or even set an alert on it. Graphite takes out the complexity of similar tools together with an easy to use API for developers so they can integrate their own self service metrics into dashboards to be used by everyone.
One last tool that deserves our attention is Logstash. Initially just a tool to aggregate, index and search the log files of our platform, it is sometimes a huge missed source of relevant information about how our applications behave.. Logstash and it's Kibana+ElasticSearch ecosystem are now quickly evolving into a real time analytics platform. Implementing the Collect, Ship+Transform, Store and Display pattern we see emerge a lot in the #monitoringlove community. Logstash now allows us to turn boring old logfiles that people only started searching upon failure into valuable information that is being used by product owners and business manager to learn from on the behavior of their users.
Together with the Graphite-based dashboards we mentioned above, these tools help people start sharing their information and communicate better. When thinking about these tools, think about what you are doing, what goals you are trying to reach and where you need to improve. Because after all, devops is not solving a technical problem, it's trying to solve a business problem and bringing better value to the end user at a more sustainable pace. And in that way the biggest tool we need to use is YOU, as the person who enables communication.